
Fictional portrayals of artificial intelligence can have a real effect on AI models, according to Anthropic.
Last year, the company said that during pre-release tests involving a fictional company, Claude Opus 4 would often try to blackmail engineers to avoid being replaced by another system. Anthropic later published research suggesting that models from other companies had similar issues with “agentic misalignment.”
Apparently Anthropic has done more work around that behavior, claiming in a post on X“We believe the original source of the behavior was internet text that portrays AI as evil and interested in self-preservation.”
The company went into more detail in a blog post stating that since Claude Haiku 4.5, Anthropic’s models “never engage in blackmail (during testing), where previous models would sometimes do so up to 96% of the time.”
What accounts for the difference? The company said it found that training on “documents about Claude’s constitution and fictional stories about AIs behaving admirably improve alignment.”
, Anthropic said that it found training to be more effective when it includes “the principles underlying aligned behavior” and not just “demonstrations of aligned behavior alone.”
“Doing both together appears to be the most effective strategy,” the company said.
Techcrunch event
San Francisco, CA
|
October 13-15, 2026
-
S&P 500 Holds Near Record Highs As Chip Stocks Rally Despite Inflation Concerns

-
Nagaland State Lottery Result: May 13, 2026, 8 PM Live - Watch Streaming Of Winners List Of Dear Dream Sambad Night Wednesday Weekly Draw

-
'Fill Up Seats Based On Class 12 Marks': Tamil Nadu CM Vijay Demands End To NEET-Based Medical Admissions After NEET-UG 2026 Cancellation

-
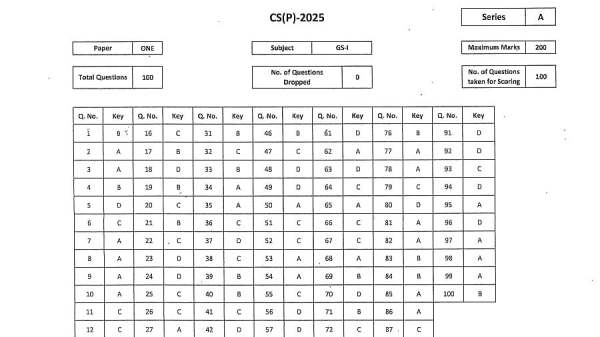
UPSC CSE Prelims Answer Key 2025 Released At upsc.gov.in; Download GS Paper 1 & CSAT PDFs
-
US SEC, Elon Musk to argue for Twitter settlement before DC judge
